Test Ortamı
Benchmark, birbirinden izole dört farklı sunucu üzerinde gerçekleştirilmiştir. Her bileşen, ölçümlerin birbirini etkilememesi için ayrı makinelere konuşlandırılmıştır.Load Generator
- 6 vCPU · 12 GB RAM · 100 GB NVMe
- wrk2 yük üretici aracı
- CentOS, tek sunucu
Upstream (Backend)
- 6 vCPU · 12 GB RAM · 100 GB NVMe
- Go tabanlı yüksek kapasiteli HTTP sunucusu (~70K RPS)
- Yük üretici ile ağ gecikmesi: ~0,5 ms
Elasticsearch
- 8 vCPU · 24 GB RAM · 200 GB NVMe
- Elasticsearch 8 — trafik log hedefi
- Gateway sunucusundan fiziksel olarak ayrı
API Gateway (Worker)
- 12 vCPU (Intel Broadwell @ 2.0 GHz) · 48 GB RAM · 250 GB NVMe
- Kubernetes üzerinde çalışır
- Yalnızca Worker pod’ları barındırır
API Manager, MongoDB ve Kubernetes master ayrı bir sunucuda çalışmaktadır. Bu bileşenler gateway performansını doğrudan etkilemez; yük testi süresince yalnızca yapılandırma verisi sağlarlar.
Gateway Kaynak Konfigürasyonları (Tier’lar)
Gateway, Kubernetes üzerinde dört farklı kaynak kısıtlamasıyla test edilmiştir. Her tier, gerçek üretim dağıtım senaryolarını temsil eder.JVM motoru tüm tier’larda G1GC’dir. Heap boyutu, Direct Memory ve GC bölge boyutu entrypoint tarafından tier’a göre otomatik belirlenir (W1/W2: Heap %60, W4/W8: Heap %65). Backend I/O ve trafik loglama Virtual Thread (VT), HTTP dispatch ise Platform Thread (PT) üzerinde çalışır.
Metodoloji
Load Generator: wrk2
Testler wrk2 ile gerçekleştirilmiştir. wrk2, koordinasyon sapmalarını (coordinated omission) önlemek amacıyla gerçek istek hızlarını izlemek üzere tasarlanmış yüksek hassasiyetli bir HTTP load generator’dır. Temel parametre — R=999999 Overload Yöntemi:R=999999 hedef hızı, gateway’in kaldırabileceği maksimum RPS’nin çok üzerinde tutulmaktadır. Bu sayede ölçülen değer “ayarlanan oran” değil, sistemin ulaşabildiği gerçek maksimum throughput’tur.
Test Parametreleri
Upstream Bottleneck Değil
Upstream sunucusu, gateway’in maksimum throughput’unun yaklaşık 4–5 katını (~70.000 RPS) işleyebilmektedir. Ölçülen tüm sınırlar gateway kapasitesinden kaynaklanmaktadır; upstream bir darboğaz oluşturmamaktadır. Yük üretici ile gateway arasındaki ağ gecikmesi ~0,5 ms olarak ölçülmüştür.ES Modları
- ES Kapalı: Trafik logları Elasticsearch’e yazılmaz. Saf gateway overhead’ini ölçer.
- ES Açık: Her istek için Elasticsearch’e asenkron trafik logu yazılır. Gerçek üretim senaryosunu simüle eder.
Sonuçlar
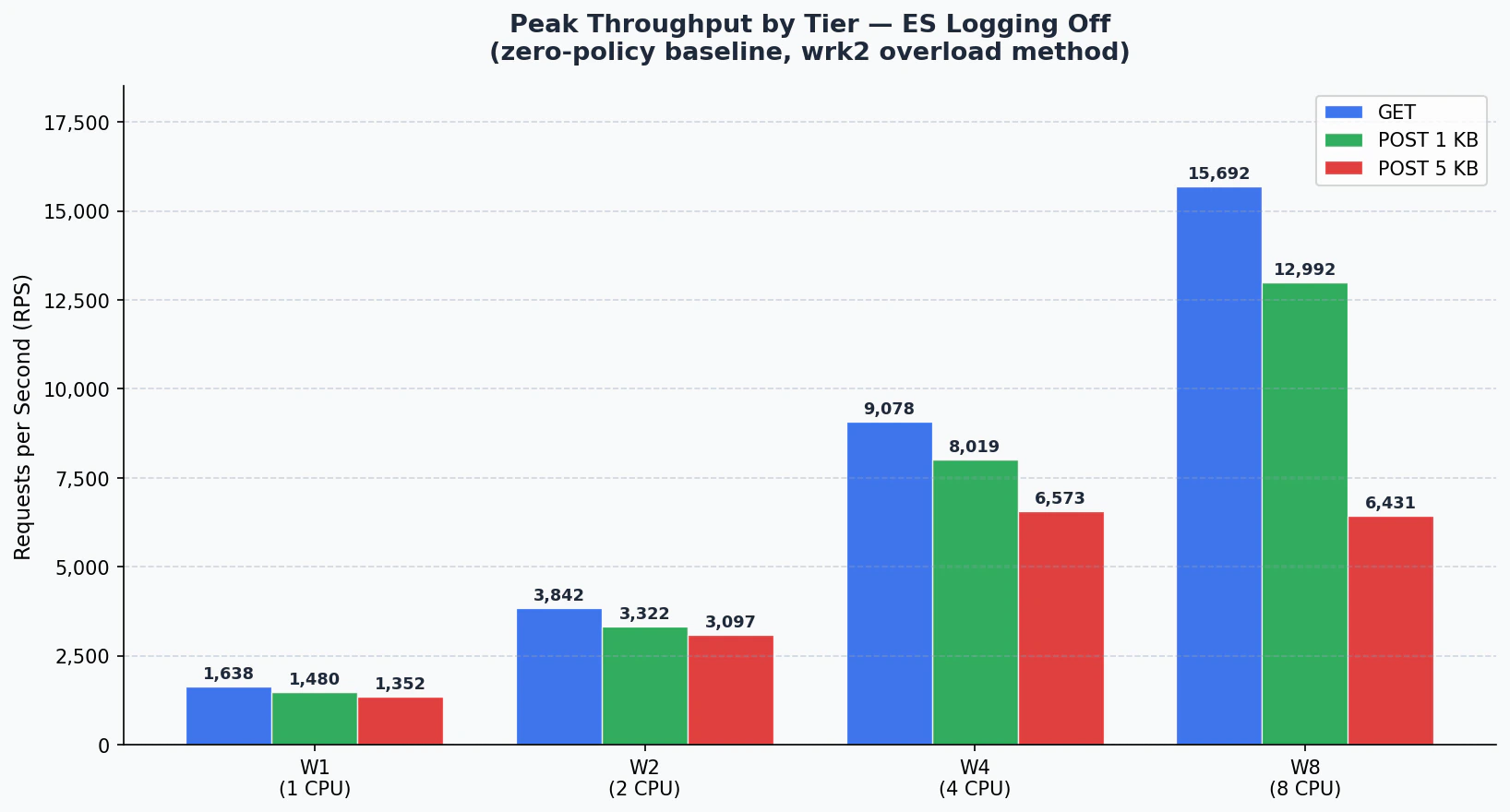
1. Peak Throughput Özeti
Her tier ve istek tipi için tüm bağlantı noktaları arasında gözlemlenen maksimum RPS değerleri.ES Kapalı
ES Açık
2. CPU Ölçekleme Verimliliği
Birim CPU başına düşen RPS ve W1’e göre ölçekleme oranı (ES kapalı, GET).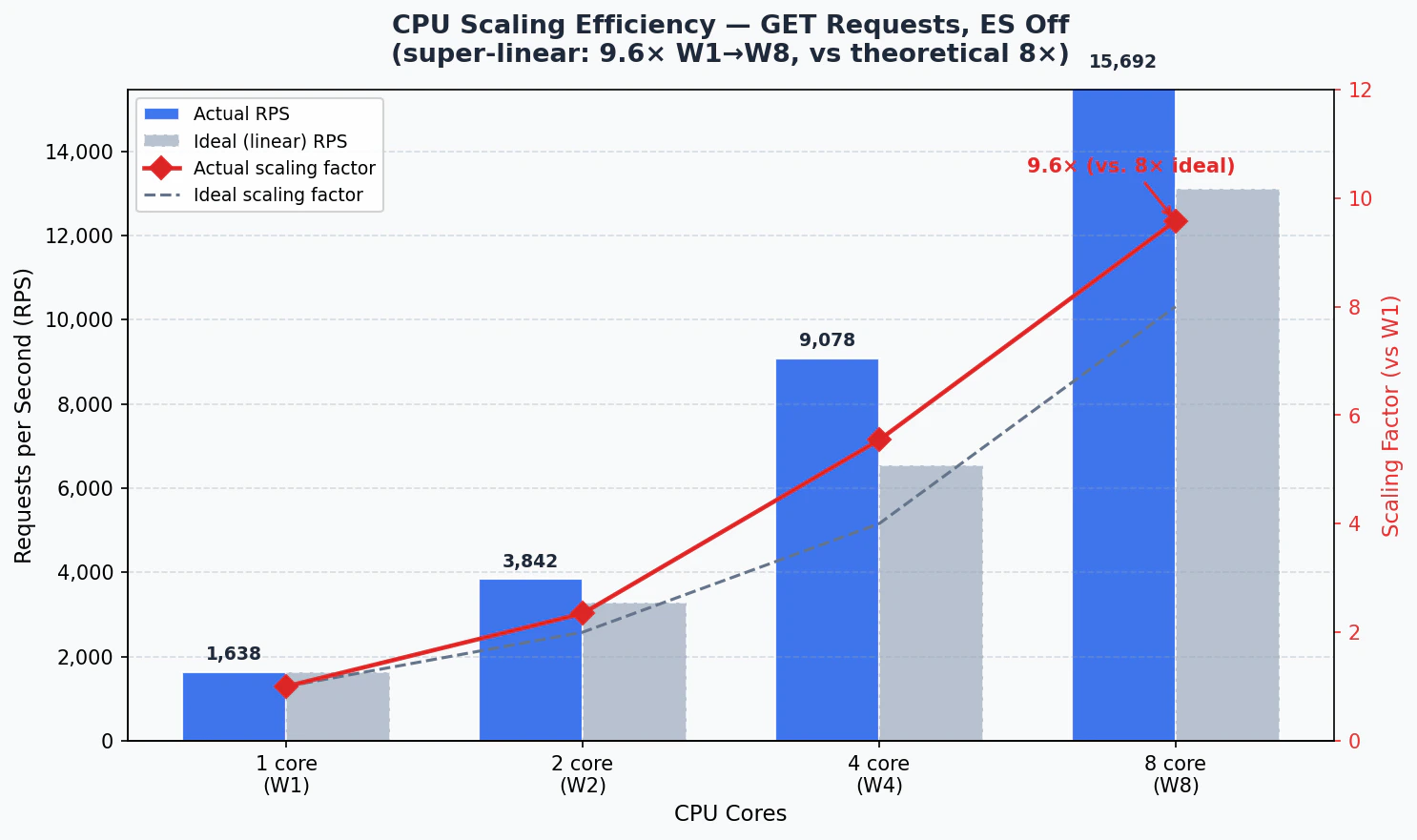
W1’den W8’e toplam artış 9,6בtir. 8 CPU için teorik ideal olan 8בin üzerine çıkılması (%120 verimlilik), gateway’in paylaşılan bağlantı havuzu ve sanal thread modeli sayesinde süper-lineer ölçeklenebildiğini göstermektedir.
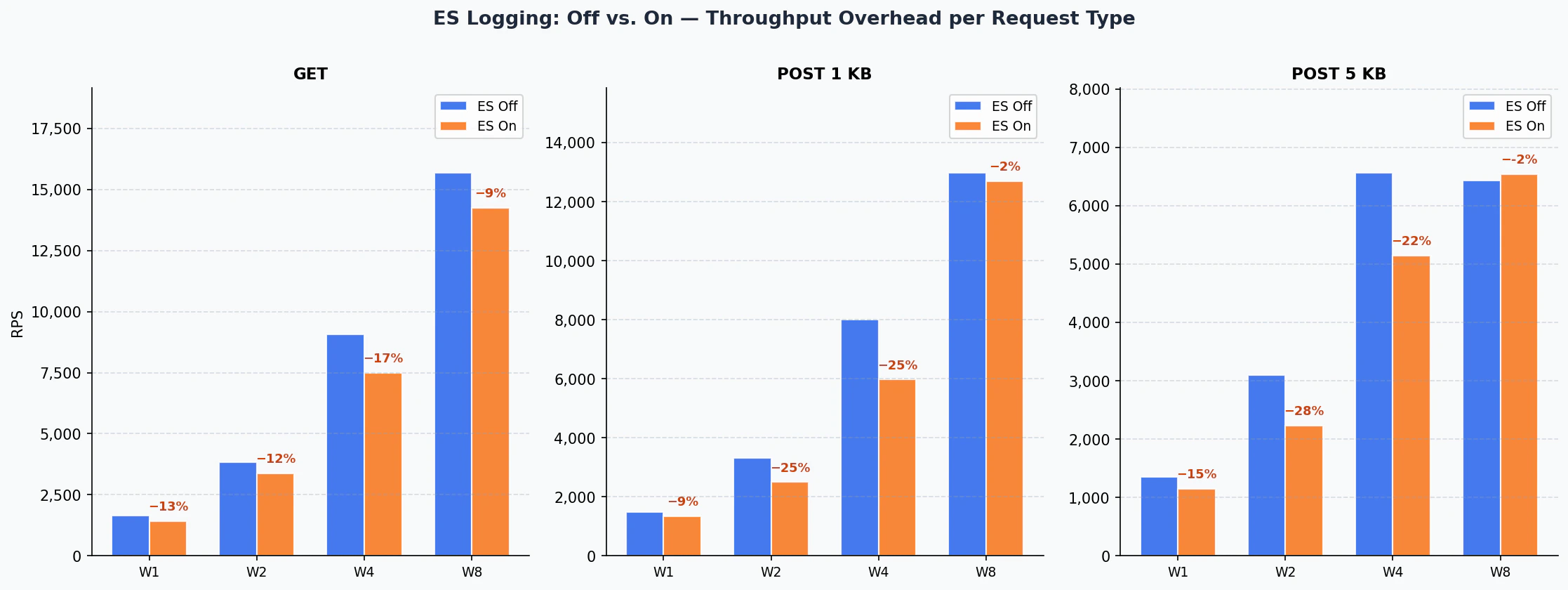
3. ES Açık / Kapalı Karşılaştırması
- GET
- POST 1KB
- POST 5KB
4. Concurrency Eğrileri (Tier Bazlı)
- W1 (1 CPU / 2GB)
- W2 (2 CPU / 2GB)
- W4 (4 CPU / 4GB)
- W8 (8 CPU / 8GB)
GET
POST 1KB
POST 5KB
5. JVM Diagnostics
- ES Kapalı
- ES Açık
Tüm tier ve modlarda Blocked thread sayısı 0 kalmıştır. Deadlock veya kaynak çakışması yaşanmamıştır.
Politika Performans Etkisi
Benchmark sonuçları politika içermeyen saf yönlendirme senaryosunu ölçmektedir. Gerçek üretim senaryolarında her politika, kendi mekanizmasına bağlı olarak farklı bir maliyet kalemi ekler. Bu maliyetler iki temel kategoriye ayrılır: CPU yükü ve harici gecikme (latency).CPU-Yoğun Politikalar — Throughput Düşürür
Bu politikalar her istek için gateway üzerinde hesaplama yapar. CPU doğrudan tüketilir; tier büyütülerek veya yatay ölçeklenerek telafi edilebilir.XML / XSD Şema Doğrulama
XML / XSD Şema Doğrulama
İstek veya yanıt gövdesi, yüklenen XSD şemasına göre her çağrıda parse edilip doğrulanır. Şema karmaşıklığı ve mesaj boyutu doğrusal biçimde CPU tüketimi artırır.Örneğin 50KB XML gövdeli bir istekte karmaşık bir XSD şeması, ek politika olmaksızın bile throughput’u %30–60 oranında düşürebilir. Şema basit ve mesajlar küçükse etki sınırlı kalır.
XML Dönüştürme (XSLT)
XML Dönüştürme (XSLT)
XSLT, gateway üzerinde her istek için tam bir XML ayrıştırma ve şablon dönüştürme döngüsü çalıştırır. Karmaşık bir XSLT şablonu, CPU kullanımını tek başına ikiye katlamak için yeterlidir.XSLT 1.0 ile 2.0 arasında işlem maliyeti önemli ölçüde farklılaşır. Büyük mesajlarda ya da sıkça tetiklenen endpoint’lerde W4 veya üzeri tier tercih edilmelidir.
JSON Şema Doğrulama
JSON Şema Doğrulama
XSD doğrulamasının JSON eşdeğeridir. JSON body her istek için parse edilir ve tanımlı JSON Şema kurallarına göre gezilir. Şema derinliği (iç içe nesne sayısı) ile mesaj boyutu CPU tüketiminin başlıca belirleyicisidir.
Şifreleme / Şifre Çözme (WS-Security, JWE)
Şifreleme / Şifre Çözme (WS-Security, JWE)
XML şifreleme, WS-Security gövde şifreleme veya JWE token şifresi çözme işlemleri, kriptografik işlemler içerdiğinden CPU kullanımını önemli ölçüde artırır. Özellikle asimetrik şifreleme (RSA) simetrik (AES) seçeneklere göre çok daha yüksek maliyetlidir.
Dijital İmza ve İmza Doğrulama (WS-Security, JOSE)
Dijital İmza ve İmza Doğrulama (WS-Security, JOSE)
Her istek için imza hesaplanması ya da doğrulanması kriptografik işlem gerektirir. RSA-2048 veya RSA-4096 tabanlı imzalar, HMAC tabanlı alternatiflere kıyasla throughput üzerinde belirgin bir baskı oluşturur. Yüksek trafikli endpoint’lerde imza algoritması seçimi dikkatli yapılmalıdır.
İçerik Filtresi (Content Filtering)
İçerik Filtresi (Content Filtering)
Gövde içeriğini regex veya özelleştirilebilir kurallara göre tararken tüm mesaj her istek için değerlendirilir. Kural sayısı arttıkça ve mesaj büyüdükçe CPU maliyeti katlanarak artar.
Script Politikası (Groovy)
Script Politikası (Groovy)
Groovy script’leri JVM üzerinde çalışır ancak başlangıç derleme maliyeti script cache ile azaltılmıştır. Bununla birlikte script içeriğinin karmaşıklığı doğrudan CPU kullanımını belirler. Döngü, parse ve hesaplama yoğun scriptler throughput’u ciddi ölçüde düşürebilir.
Harici Gecikme Ekleyen Politikalar — Yanıt Süresi Uzar
Bu politikalar bir dış sisteme bağlanarak işlem yapar. Gateway CPU’su büyük ölçüde boşta beklerken, yanıt süresi harici sistemin gecikmesi kadar uzar. CPU büyütmek bu tür gecikmeyi azaltmaz; harici sistemin performansı ve ağ gecikmesi belirleyicidir.LDAP Kimlik Doğrulama
LDAP Kimlik Doğrulama
Her istek için LDAP sunucusuna bağlanarak kullanıcı adı ve parola doğrulaması yapılır. LDAP sunucusuna gidiş-dönüş ağ gecikmesi (tipik olarak 1–10 ms) her isteğe eklenir. LDAP havuzu olmayan yapılandırmalarda bağlantı kurulum maliyeti de istek başına düşer.LDAP sunucusu gateway ile aynı veri merkezindeyse etki nispeten sınırlı kalır; farklı veri merkezlerinde veya bulut ortamlarında gecikme onlarca milisaniyeye çıkabilir ve throughput orantısız biçimde düşer.
OAuth2 Token İntrospeksiyonu / OIDC
OAuth2 Token İntrospeksiyonu / OIDC
Token her istek için yetkilendirme sunucusuna (Authorization Server) gönderilerek doğrulatılır. Yanıt süresi tamamen AS’nin yanıt hızına bağlıdır. Token cache etkinleştirilmezse bu durum hem throughput hem latency üzerinde ciddi baskı oluşturur.Token cache kullanıldığında cache miss oranına bağlı olarak maliyet önemli ölçüde azaltılabilir. Cache TTL’i iş gereksinimlerine göre dikkatli ayarlanmalıdır.
JWT (Uzak JWKS Doğrulaması)
JWT (Uzak JWKS Doğrulaması)
İmza anahtarının uzak JWKS endpoint’inden alınması gerekiyorsa, her anahtar getirme işlemi ağ çağrısı anlamına gelir. JWKS cache etkinleştirildiğinde bu maliyet büyük ölçüde ortadan kalkar; cache süresi dolmadıkça ek gecikme oluşmaz.
SAML Kimlik Doğrulama
SAML Kimlik Doğrulama
SAML assertion’larının IdP (Identity Provider) üzerinde doğrulanması gerekiyorsa harici bağlantı kaçınılmazdır. WS-Trust veya SOAP tabanlı IdP çağrıları hem ağ gecikmesi hem de işlem maliyeti ekler.
Backend Kimlik Doğrulama (Basic / API Key / Token)
Backend Kimlik Doğrulama (Basic / API Key / Token)
Backend servisine iletilen kimlik doğrulama bilgilerinin her istekte yenilenmesi ya da doğrulanması gerekiyorsa (örneğin dinamik token alma) ek bir harici çağrı gerçekleşir. Statik kimlik bilgileri kullanıldığında bu maliyet oluşmaz.
API Çağrısı Politikası
API Çağrısı Politikası
Politika akışı içinde başka bir API’ye çağrı yapılması, o API’nin yanıt süresi kadar gecikme ekler. Seri birden fazla API çağrısı latency’yi katlar. Koşullu çalıştırma ve sonuç cache’leme ile bu maliyet minimize edilebilir.
Düşük Maliyetli Politikalar
Aşağıdaki politikalar gateway üzerinde minimal CPU ve sıfır harici gecikme ekler. Yüksek trafikli ortamlarda bile performans üzerindeki etkileri genellikle ihmal edilebilir düzeydedir.IP İzin / Yasaklama Listesi
Gelen IP adresi in-memory liste ile karşılaştırılır. Mikrosaniye mertebesinde tamamlanır.
Hız Sınırlama / Kota
Lokal sayaçlara veya paylaşılan önbelleğe karşı sayım yapılır. Önbellek entegrasyonu yoksa saf in-memory işlemdir.
Header Manipülasyonu
Belirli header’ların eklenmesi, silinmesi veya değiştirilmesi string işlemleridir; CPU maliyeti ihmal edilebilir.
Basic Kimlik Doğrulama (Yerel)
Kimlik bilgileri gateway’de tanımlıysa ve harici LDAP/dizin servisi yoksa, doğrulama tamamen in-memory gerçekleşir.
Değerlendirme
CPU Ölçekleme: Süper-Lineer Verimlilik
CPU Ölçekleme: Süper-Lineer Verimlilik
W1’den W8’e geçişte GET throughput’u 9,6× artmıştır. Teorik ideal olan 8בin üzerine çıkılması (%120 verimlilik), paylaşılan bağlantı havuzu ve Java sanal thread modelinin birlikte sağladığı süper-lineer ölçeklenme kapasitesini göstermektedir.
Elasticsearch Loglama Maliyeti
Elasticsearch Loglama Maliyeti
ES loglama maliyeti tier büyüdükçe orantısız biçimde azalmaktadır. W8’de GET için yalnızca %9, POST 1KB için %2 throughput kaybı gözlemlenmektedir. 8 CPU’nun sağladığı asenkron işleme kapasitesi ES yazma gecikmesini büyük ölçüde absorbe etmektedir.
Politika Tasarımı için Mimari Öneri
Politika Tasarımı için Mimari Öneri
CPU-yoğun politikaları (XSLT, şifreleme, şema doğrulama) koşullu çalıştırma ile yalnızca gerekli endpoint’lere sınırlayın. Harici gecikme ekleyen politikaları (LDAP, OAuth2 introspeksiyon) token/sonuç önbelleği ile destekleyin. Bu iki önlem birlikte uygulandığında politika maliyetinin büyük bölümü ortadan kalkar.
Kapasite Planlama Rehberi
Kapasite Planlama Rehberi
Aşağıdaki değerler yalnızca yönlendirme + ES loglama içeren saf senaryoyu temsil eder. Politika yükü eklendiğinde gerçek kapasite bu değerlerin altında olacaktır.
Cache Performansı
Cache bileşeni, API yanıtlarını bellekte saklayarak tekrarlayan istekleri backend’e iletmeden doğrudan yanıtlar. Aşağıdaki sonuçlar, cache bileşeninin farklı kaynak konfigürasyonlarında GET (okuma) ve PUT (yazma) işlemlerindeki maksimum kapasitesini göstermektedir.Cache bileşeni Hazelcast tabanlıdır ve ZGC çöp toplayıcı ile çalışır. JVM parametreleri her tier için entrypoint tarafından otomatik belirlenir. Test metodolojisi gateway benchmark ile aynıdır (R=999999 overload, wrk2).
Cache Kaynak Konfigürasyonları
Maksimum Throughput
CPU Ölçeklenme Verimi
W1’den W8’e toplam artış GET için 6.3×, PUT için 6.6× olup CPU artışına (8×) yakın bir ölçeklenme göstermektedir. PUT işlemleri W8’de GET ile neredeyse eşit performansa ulaşarak yazma darboğazının yüksek CPU ile ortadan kalktığını göstermektedir.
Cache Kapasite Planlama
Benchmark Sürümü: v1 · Test Tarihi: 27 Mart 2026 · Metodoloji: R=999999 overload, 300 s × 1 tekrar · Ortam: Kubernetes (isolated pod), Hazelcast 5.5 + Java 25 ZGC
Sonraki Adımlar
Kapasite Planlama
Donanım gereksinimlerini ve boyutlandırma rehberini inceleyin
Deployment Topolojileri
Deployment topolojilerini ve yüksek erişilebilirlik seçeneklerini inceleyin
Politika Nedir?
Politika türleri ve uygulama mekanizması hakkında detaylı bilgi edinin
Mesaj İşleme ve Politika Uygulama
Gateway’in istek akışını ve politika sıralamasını öğrenin
Benchmark Sürümü: v8 · Test Tarihi: 14 Mart 2026 · Metodoloji: R=999999 overload, 300 s × 3 tekrar · Ortam: Kubernetes (isolated pod), Undertow + Java 25 Virtual Threads